GCP 입문부터 인프라 구축까지
그동안 NCP와 AWS를 사용해왔는데, 이번에 GCP를 사용할 일이 생겨서 기초부터 정리하고 실제 인프라를 구축해보기로 했다. GCP의 계층 구조부터 VPC, VM, Cloud SQL까지 구축하면서 다른 클라우드와 다르다고 느꼈던 부분들을 기록해보자.
GCP 계층 구조
GCP는 리소스를 관리하는 계층 구조가 좀 독특하다. AWS와 비교하면 확실히 다른 느낌이다.
Organization
└─ Folder
└─ Project
└─ Resource
Organization
- 조직의 최상위 단위. 하나의 도메인을 기반으로 생성
- 도메인 소유권을 증명하면 GCP Console에 조직이 생성된다
- IAM, Billing, 정책 관리의 기준점이 된다
Folder
- 부서, 서비스, 환경별로 구분하여 프로젝트를 정리할수있는 중간 단위
- 계층적 구조라서 상속 기반으로 IAM/정책 적용이 가능하다
Project
- 리소스 생성과 운영의 기본 단위. VM, Storage, GKE 등이 프로젝트 하위에 존재한다
- 결제도 이 단위에서 연결된다
Resource
- 실질적인 사용 자원 (VM, Cloud SQL, Storage 등)
- 반드시 하나의 프로젝트에 소속된다
AWS에서는 계정 단위로 리소스를 관리하는 느낌이라면, GCP는 Organization > Folder > Project 구조로 좀더 명확하게 계층이 나뉘어 있다. 팀이 크거나 환경(dev/staging/prod)이 여러개인 경우 이 구조가 꽤 유용하다.
IAM 기본 개념
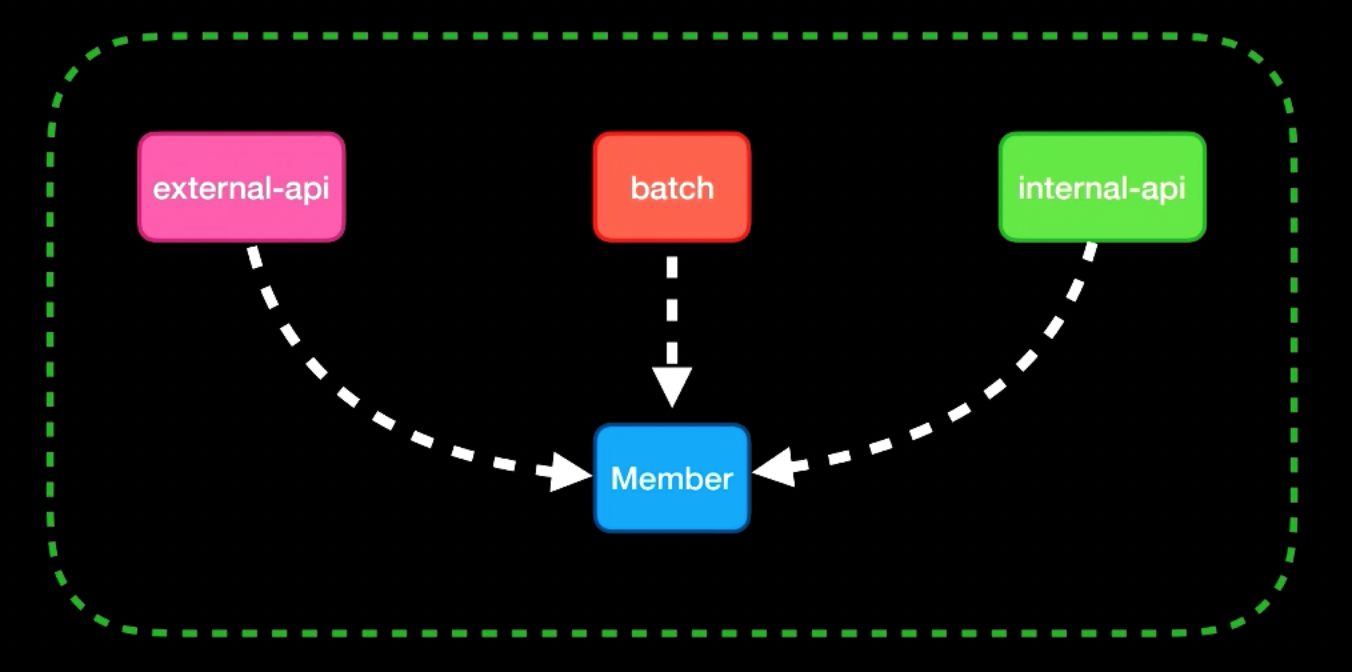
GCP의 IAM은 누가(Who) 무엇을(What) 어디에(Where) 접근할수있는지를 정의한다.
Member + Role → Resource
- Member: Google 계정, 서비스 계정, 그룹 등
- Role: 권한의 묶음 (Viewer, Editor, Owner 또는 커스텀 역할)
- Resource: 역할이 적용되는 대상 (프로젝트, 폴더, 개별 리소스)
주의할 점은 Role이 상위 계층에서 하위로 상속된다는 것이다. Organization에 Editor를 부여하면 하위 모든 프로젝트에 적용되니까, 최소 권한 원칙을 지키려면 가능한 낮은 계층에서 역할을 부여하자.
서비스 계정
실제 인프라를 구축하면 애플리케이션이 GCP API에 접근해야하는 상황이 생긴다. 이때 사용하는게 Service Account다.
# 서비스 계정 생성
gcloud iam service-accounts create my-app-sa \
--display-name="My App Service Account"
# 역할 부여
gcloud projects add-iam-policy-binding my-project \
--member="serviceAccount:my-app-sa@my-project.iam.gserviceaccount.com" \
--role="roles/cloudsql.client"
# 키 파일 생성
gcloud iam service-accounts keys create key.json \
--iam-account=my-app-sa@my-project.iam.gserviceaccount.com
하지만 키 파일은 유출되면 큰 문제가 생기니까 가능하면 Workload Identity를 사용하는게 좋다.
VPC 구축
GCP의 VPC는 AWS와 다르게 글로벌 리소스다. 하나의 VPC가 여러 리전에 걸쳐서 존재할수있다.
# VPC 생성
gcloud compute networks create my-vpc \
--subnet-mode=custom
# 서브넷 생성 (서울 리전)
gcloud compute networks subnets create my-subnet \
--network=my-vpc \
--region=asia-northeast3 \
--range=10.0.1.0/24
AWS에서는 VPC가 리전에 종속되어있어서, 다른 리전끼리 통신하려면 VPC Peering이 필요하다. 하지만 GCP는 같은 VPC 안에서 리전이 달라도 내부 통신이 가능하다. 이게 꽤 편하다.
방화벽 규칙
GCP에서는 Security Group 대신 Firewall Rules를 사용한다. VPC 단위로 적용되고, 태그 기반으로 대상을 지정할수있다.
# SSH 허용
gcloud compute firewall-rules create allow-ssh \
--network=my-vpc \
--allow=tcp:22 \
--source-ranges=0.0.0.0/0 \
--target-tags=allow-ssh
# 내부 통신 허용
gcloud compute firewall-rules create allow-internal \
--network=my-vpc \
--allow=tcp,udp,icmp \
--source-ranges=10.0.0.0/16
target-tags로 특정 태그가 붙은 VM에만 규칙을 적용할수있다. AWS의 Security Group과 비슷하지만, 네트워크 레벨에서 동작한다는 차이가 있다.
Compute Engine (VM) 생성
gcloud compute instances create my-server \
--zone=asia-northeast3-a \
--machine-type=e2-medium \
--subnet=my-subnet \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--boot-disk-size=50GB \
--tags=allow-ssh
접속은 gcloud compute ssh로 간단하게 가능하다.
gcloud compute ssh my-server --zone=asia-northeast3-a
AWS에서는 키페어 관리가 번거로운데, GCP는 gcloud ssh가 자동으로 키를 관리해줘서 편하다. 하지만 프로덕션 환경에서는 OS Login을 설정해서 IAM 기반으로 SSH 접근을 관리하는게 좋다.
Cloud SQL 구축
Cloud SQL은 GCP의 관리형 RDB 서비스다. MySQL, PostgreSQL, SQL Server를 지원한다.
# Cloud SQL 인스턴스 생성 (MySQL)
gcloud sql instances create my-db \
--database-version=MYSQL_8_0 \
--tier=db-custom-2-4096 \
--region=asia-northeast3 \
--network=my-vpc \
--no-assign-ip
--no-assign-ip를 주면 퍼블릭 IP 없이 내부 IP만 할당된다. 보안상 이렇게 설정하는게 맞다.
# 데이터베이스 생성
gcloud sql databases create mydb --instance=my-db
# 사용자 생성
gcloud sql users create admin \
--instance=my-db \
--password=비밀번호
Private IP 접근 설정
Cloud SQL에 Private IP로 접근하려면 Private Service Access를 설정해야한다.
# Private Service Access 설정
gcloud compute addresses create google-managed-services \
--global \
--purpose=VPC_PEERING \
--prefix-length=16 \
--network=my-vpc
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services \
--network=my-vpc
이 설정을 하면 같은 VPC 내의 VM에서 Cloud SQL의 Private IP로 직접 접근이 가능해�진다.
Spring Boot 연동
spring:
datasource:
url: jdbc:mysql://10.x.x.x:3306/mydb
username: admin
password: ${DB_PASSWORD}
driver-class-name: com.mysql.cj.jdbc.Driver
VM에서 Cloud SQL로의 접근이 정상적으로 되는지 먼저 확인하자.
mysql -h 10.x.x.x -u admin -p
AWS vs GCP 느낀점
실제로 구축해보면서 느낀 차이점을 정리해보자.
| 항목 | AWS | GCP |
|---|---|---|
| VPC | 리전 종속 | 글로벌 |
| 방화벽 | Security Group (인스턴스 단위) | Firewall Rules (네트워크 단위, 태그 기반) |
| SSH | 키페어 직접 관리 | gcloud ssh 자동 관리 |
| CLI | aws-cli | gcloud (좀더 직관적) |
| 콘솔 UI | 복잡하지만 기능 많음 | 깔끔하지만 가끔 메뉴 찾기 어려움 |
개인적으로 gcloud CLI가 AWS CLI보다 직관적이라고 느꼈다. gcloud compute instances create 같은 명령어가 뭘 하는건지 바로 읽힌다. 하지만 한국 리전 기준으로 서비스 종류나 레퍼런스는 AWS가 아직 압도적으로 많다.
마무리
NCP, AWS를 거쳐서 GCP까지 써보니 클라우드마다 확실히 철학이 다르다는걸 느꼈다. GCP는 글로벌 VPC나 IAM 상속 구조처럼 큰 조직에서 관리하기 좋은 방향으로 설계된 느낌이다. 하지만 실무에서는 결국 팀이 익숙한 클라우드를 쓰는게 가장 효율적이고, 중요한건 어떤 클라우드를 쓰든 네트워크와 보안 기본기를 탄탄히 갖추는것이라고 생각한다.