UUID를 PK로 사용하면 안됩니다.
회사에서 레거시 코드를 보던 도중 PK를 로 관리하고 있다는 것을 알게 되었다. 를 사용하는 이유에 대해 찾아보던 중 새롭게 알게된 내용과 어떻게 사용하는 것이 효율적인지 기록해보…
회사에서 레거시 코드를 보던 도중 PK를 UUID로 관리하고 있다는 것을 알게 되었다. UUID를 사용하는 이유에 대해 찾아보던 중 새롭게 알게된 내용과 어떻게 사용하는 것이 효율적인지 기록해보려고 한다.
UUID 란?
UUID(Universally Unique Identifier) 는 전세계적으로 고유한 식별자를 생성하는 표준화된 방법이다. 분산시스템 등에서 중복되지 않는 유일한 값을 구성할때 사용되는 고유한 식별자이다. 128bit의 길이를 가지고, 32자리의 16진수로 표현된다. 일반적으로 8-4-4-4-12 형식으로 구분된 문자열로 나타난다.
UUID 구성
UUID는 다양한 방법으로 생성이 가능한데, 표준에 따르면 다양한 버전을 가지고 있다. 총 5개의 버전으로 출시년도에 따라서 버전이 존재한다.
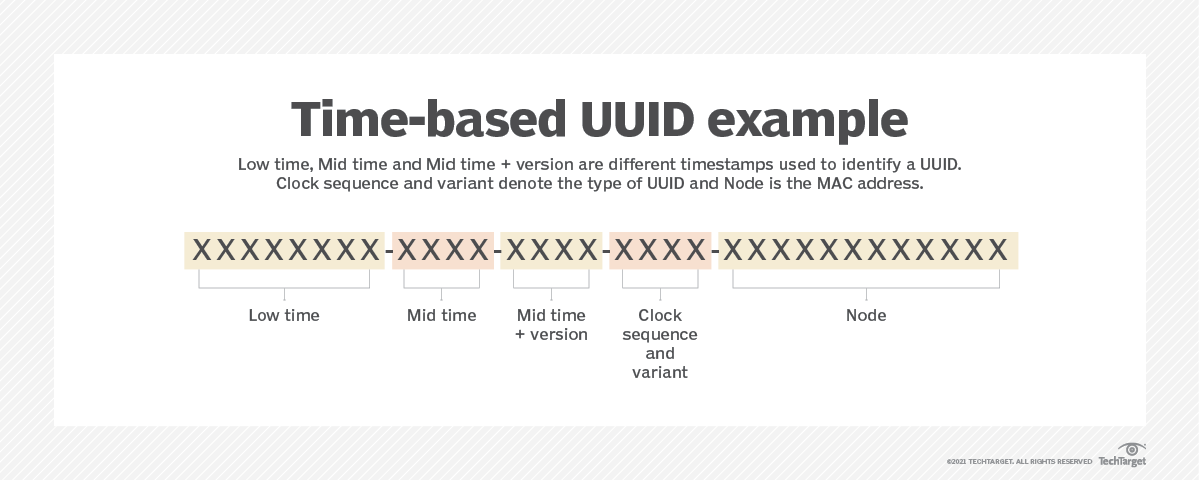
- UUID Version 1.
- "현재시간" / "랜덤한 MAC주소"를 기반으로 생성
- 유일성이 보장되지만 보안에 취약
- 시간과 노드를 기반으로 생성
- 60bit : UTC Time
- 48bit : node(MAC 주소)
- 16bit : Sequence 번호(중복방지를 위해)
- UUID Version 2.
- UUID Version 1.의 확장 버전
- POSIX UID / GID 등의 정보를 포함
- 일반적으로 사용되지 않음
- UUID Version 3.
- 이름 기반의 UUID
- 이름과 네임스페이스를
해시함수(MD5)로 해싱하여 생성 - 동일한 입력에 대해 동일한 출력을 보장
- 암호화 해시함수를 사용하여 보안성이 높음
- UUID Version 4.
- 랜덤한 무작위 숫자발생기를 사용해 생성
- 완전한 무작위 값으로 생성되며 생성속도가 빠름
- 보안성이 높고 이론적으로 중복될 가능성이 낮음
- UUID Version 5.
- Version 3.와 유사하지만
SHA-1해시함수를 사용하여 이름기반으로 생성
- Version 3.와 유사하지만
UUID 사용
관계형 DB에서 데이터를 식별하기 위해 PK를 사용한다. 클라이언트와 서버 간의 데이터 확인을 위해 보통 PK를 주고 받지만 해당 방법은 보안적인 측면에서 위험성이 존재한다. 한번 예를 들어보자.
1https://www.hae02y.com/user?id=1위의 URL에서 파라미터에 들어가는 id 값을 바꿔줌으로써, 다른 사람의 정보를 확인할수있음을 예측할수있다. 이렇게 예측가능한 모델이 된다면 (Insecure Direct Object Reference, IDOR)의 위험성에 노출되게 되고, PK값을 그대로 파라미터로 사용함은 문제가 될수있다. 즉, 고유값을 같는 특정한 값으로 해당 데이터를 식별 할 필요가 있다.
서버내에서 특정한 키를 발급하거나, 세션등을 사용하여 특정 클라이언트에 한정된 고유값을 사용한다면 이를 해결할수있다. 즉, PK는 내부 시스템의 식별용으로만 사용하고, 클라이언트에게는 비즈니스용 식별자를 노출하여 해결이 가능하다. 이때 선택할수있는 옵션이 UUID이다. 또한 UUID는 고유성을 지니고 있어 여러 서버 및 프로세스에서 동시에 발급해도 겹칠 확률이 적으며, 분산 시스템 환경에서도 충돌없이 사용이 가능하다. 또한 UUID는 Stateless 한 성질을 가지고 있다. 즉, Increment PK는 데이터베이스 조회를 통해 Unique한 Key 확인이 필수이다. 이러한 방식은 분산데이터 베이스에서 SPOF(Single-Point-Of-Failure)를 발생시킬 수 도있다. 이에반해 UUID는 해당 과정을 생략하고 insert query 호출이 가능하다.
하지만 그에 반해 단점도 존재 한다. 먼저 크기가 컬럼의 데이터 사이즈가 증가한다. 기존 PK를AUTO_INCREMENT로 생성하였다면 Int(4byte) 크기에서 UUID 적용시 16byte로 증가한다. 이에 따라 인덱스의 사이즈가 증가하고 메모리부담이나 성능 저하가 발생할수있다. 또한 랜덤한 값이므로 클러스터형 Index 정렬을 방해하고, Insert 과정에서 디스크 I/O에 성능 저하를 발생 시킬수있다. 그리고 URL 요청 과정에서 UUID로 인해 URL이 길어진다.
이에 대한 첫번째 대안으로 UUID를 PK로 직접 쓰지않고, Database PK는 AUTO_INCREMENT로 두고, 클라이언트에 노출 할수있는 UUID를 설계 하는 방식 사용이 가능하다. 아니면 ULID, KSUID 등 정렬이 가능한 고유 ID를 사용하여 랜덤성과 정렬성을 모두 잡을수있다. 위 내용을 표로 간단하게 정리해보자.
| 항목 | AUTO_INCREMENT | UUID |
|---|---|---|
| 성능 | 빠름 | 느려짐 (랜덤) |
| 보안 | 예측 가능 | 예측 불가 |
| 분산 시스템 | 어려움 | 충돌 거의 없음 |
| 가독성 | O | X |
데이터의 기본키는 외부에 노출되면 안된다. INCREMENT PK, UUID 모두 상관없이 그러하다. PK를 변경하는 비용은 높지만, PK는 언젠가 변경될 수 있기 때문에, 기본키를 외부에 노출하면 이 비용은 더 높아진다. 예를 들어, 기본키가 변경되면, 외부에 공개되었던 페이지의 데이터가 조회되지 않는 현상이 발생할 수 있다. Software에서 절대로 변경되지 않는 것은 없다. 예를 들어, 데이터가 많아져서 저장소를 RDBMS에서 NoSQL으로 이전하게 되는 경우, PK가 숫자형에서 문자형으로 변경될 수 있다.
애플리케이션 내부용 키로는 INCREMENT PK를, 외부에 공개할 키로는 UUID를 사용하는 것을 권장한다. 애플리케이션 내부에서는 INCREMENT PK를 사용하여 관계 데이터를 참조하면 성능과 저장 장소 측면에서 이점을 얻을 수 있다. 식별값이 노출되는 서비스가 내부시스템일지라도 UUID으로 데이터를 식별하는 것이 좋다. 외부에 공개될 식별자로 UUID를 사용하게되면, 향후에 내부 기본키를 변경해야하더라도 영향범위를 데이터베이스로 한정지을 수 있다. UUID가 사용자 친화적이지 않아서, URL에 붙여서 사용할 수 없는 경우가 있다. 이 때에는 slug를 사용하여 사용자 친화적인 URL패턴을 만들면 된다. 만약 slug가 중복된다면, 뒤에 해시값을 붙여서 대체 식별자를 만들 수 있다. 블로그에서 URL에 글의 제목을 활용하는 사례가 이와 같은 방식이다.
ULID / KSUID 란?
둘 다 UUID의 단점을 보완하기 위해 나온 고유 ID 생성 규격이다.
ULID : Universally Unique Lexicographically Sortable Identifier
- 의미: UUID처럼 유니크하지만, 문자열이 시간 순 정렬 가능
- 형식:
01FZV9YJ00X4M2YH6Y3M1QGJVT - 내부 구조: 상위 비트: 타임스탬프 / 하위 비트: 랜덤값
- 시간 순서대로 생성 → DB 인덱스 정렬 효율적
- 보통
26자 Base32 문자열 - 공간 효율성: UUID와 비슷하지만, 읽고 쓸 때 더 빠름
- 사용 예: Firebase Firestore, 일부 NoSQL, 이벤트 소싱
KSUID : K-Sortable Unique Identifier
- 의미: 쿠팡/Stripe 등에서 사용, UUID처럼 유니크하면서도 정렬 가능한 ID
- 형식:
0o5Fs0EELR0fUjHjbCnE8v0X9Ey - 내부 구조: 첫 4바이트: 생성 시간 (Unix epoch) / 나머지 16바이트: 랜덤값
- 결과적으로 시간순 정렬 가능 & UUID와 동일한 20바이트
- 고유성 보장 + 시간 순 정렬성
- RDB → INT PK + UUID 외부 노출 or ULID/KSUID
- NoSQL/분산 → ULID/KSUID 더 적합
사용 예시
내가 주로 사용하는 Java에서는 UUID Version 1,3,4를 지원한다. 이를 사용하는 예시를 작성해보았다.
참고 : UUID Java Docs
UUID Version 3.
1import java.util.UUID;2
3public static UUID generateType3UUID() {4 String name = "example name";5 UUID uuid3 = UUID.nameUUIDFromBytes(name.getBytes());6 System.out.println("Version 3 UUID: " + uuid3);7 return uuid3;8}UUID Version 4.
1import java.util.UUID;2
3public static UUID generateType4UUID() {4 // 버전 4 UUID 생성하기5 UUID uuid4 = UUID.randomUUID();6 System.out.println("Version 4 UUID: " + uuid4); // Version 4 UUID: c48b2aef-9d79-44fe-bd97-46fd313610697 return uuid4;8}UUID Version 5.
1import java.util.UUID;2
3String name = "example_name";4UUID namespace = UUID.fromString("00000000-0000-0000-0000-000000000000");5UUID uuid = createUUIDv5(name, namespace); // 함수를 호출합니다6
7public static UUID createUUIDv5(String name, UUID namespace) {8
9 UUID uuid = createUUIDv5(name, namespace); // 함수를 호출합니다10
11 byte[] nameBytes = name.getBytes(StandardCharsets.UTF_8);12 byte[] namespaceBytes = namespace.toString().getBytes(StandardCharsets.UTF_8);13 byte[] bytesToHash = new byte[nameBytes.length + namespaceBytes.length];14
15 System.arraycopy(nameBytes, 0, bytesToHash, 0, nameBytes.length);16 System.arraycopy(namespaceBytes, 0, bytesToHash, nameBytes.length, namespaceBytes.length);17
18 try {19 MessageDigest md = MessageDigest.getInstance("SHA-1");20 byte[] hash = md.digest(bytesToHash);21 hash[6] &= 0x0f;22 hash[6] |= 0x50;23 hash[8] &= 0x3f;24 hash[8] |= 0x80;25 return UUID.nameUUIDFromBytes(hash);26 } catch (NoSuchAlgorithmException e) {27 throw new RuntimeException("Error creating UUID v5", e);28 }29}결론
우리 회사에서 레거시에 사용된 UUID는 어쩌면 잘못 사용 되고 있을수도 있다는 생각이 들었다. 모든 테이블의 PK를 UUID를 통해 생성 하였는데, 특히 주차면 테이블의 경우 꽤나 많은 양의 데이터를 관리중이고 PK를 통해 각 주차면에 데이터에 접근해야하는 경우가 많다. 이 과정에서 UUID의 도입은 오히려 조회 성능을 악화 시키는 방식이지 않을까 하는 생각이 든다. 이러한 내용을 바탕으로 레거시 전환 과정에서 PK의 사용과 관련 된 부분을 수정해보려고 한다. 오늘 공부한 내용을 한줄로 요약하면 다음과 같다.
- 애플리케이션 내부용 키로는
INREMENT PK를, 외부에 공개할 키로는UUID를 사용하는 것을 권장 - PK는 외부에 노출되지않는 것이 중요