사내에 TIG스택을 도입하며 (Telegraf + InfluxDB + Grafana)
입사 이후 운영중인 환경을 보면서 사내에 모니터링 시스템을 제대로 구축해야되겠다는 생각을 하게 되었다. 모니터링 시스템이 없는 환경에서 서버에 하나씩 을 날려보고, 로그를 확인하는…
입사 이후 운영중인 환경을 보면서 사내에 모니터링 시스템을 제대로 구축해야되겠다는 생각을 하게 되었다. 모니터링 시스템이 없는 환경에서 서버에 하나씩 Ping을 날려보고, 로그를 확인하는 방식으로 운영을 하고 있는 현재 상태를 우선적으로 바꿔야할 필요성을 느꼈다.

특히 클라이언트측에서 VoC가 들어온뒤, 장애 대응을 진행하는 프로세스가 가장 큰 문제라고 생각된다. 즉 사후 대응이 아닌 사전 대응이 절대적으로 필요한 상황이였다. 다양한 모니터링을 위한 방법을 고민하면서 그리고 실제로 사내에 도입해가면서 알게되었던 경험을 블로그에 적어보고자 한다.
시스템 운영 환경에서 가장 큰 목표는 시스템의 정상적인 구동이다. 인프라팀에서 장애 발생시 해당 팀에서 정한 룰을 기반으로 현장에 방문하거나, 원격을 통하여 대응을 진행하지만 개발자가 만들어낸 환경에서 정상적으로 서비스가 동작 하는지 여부는 파악이 필요하다고 생각한다.
모니터링을 정상적으로 진행하기 위해 다각도로 고민을 하고있었는데 결론적으로 인프라팀에서 가장 우선시 되는 요구사항을 운영환경에 적용하는게 낫다는 판단이 들었다. 먼저 CPU, Memory, Ping 등 메트릭 데이터에 대한 모니터링이 우선시 되야한다는 생각이 들었다. 사내 구조에서 프로그램에 대한 문제나 장애 대응은 로그 분석등을 통해 처리가 가능하지만, On-Premise 환경으로 현장에 구축된 서버들에 대해 1차 적인 파악이 안되기 때문이다.
해당 부분을 우선 구축하고 추후에 ELK와 같은 모니터링 스택을 도입하기로 결정하였다. 그럼 이둘의 차이점을 간단하게 알아보자
TIG 스택

ELK 스택

본론으로
위에서 설명한 이유를 바탕으로 Telegraf + InfluxDB + Grafana 도입을 결정했다. 그럼 각각의 서비스가 어떤 부분을 담당하는지 알아보자.
Telegraf

Telegraf의 장점은 수많은 플러그인(Inputs, Outputs, Processors, Aggregators)을 제공한다는 점이다. 즉, 단순히 시스템 리소스뿐 아니라 DB 모니터링, 애플리케이션 지표 수집, 심지어 외부 API 호출까지 커버할 수 있다. Telegraf를 사용하는 방법은 공식 문서에 정리되어있으니 구축시 참고하자.
InfluxDB

TSDB는 일정한 주기를 가지고 수집되는 대량의 데이터를 처리한다. 예시로 Melon DevOps 구성사례를 확인할수있다.
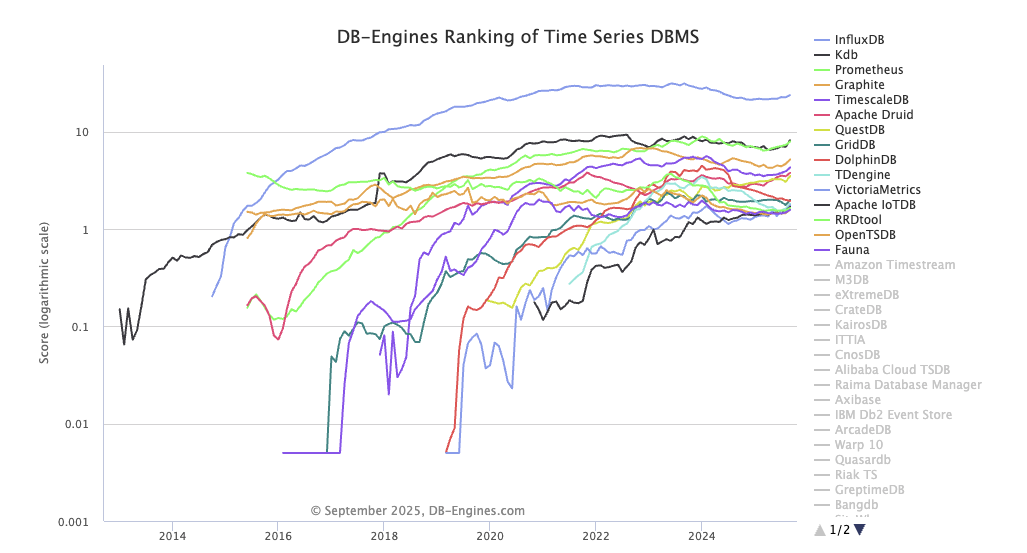
CPU 사용률이나 메모리 사용량 같은 값은 매 초/분 단위로 쌓이기 때문에, 빠른 읽기·쓰기와 압축·보존정책이 중요하다. InfluxDB는 이런 요구사항을 해결해주는 저장소이며 TSDB중 가장 높은 점유율을 가지고있는데자료를 보면 2025년 9월기준 압도적으로 1위이다.
글을 처음 작성할 당시 InfuxDB 2까지 지원을 했었는데 현재는 InfluxDB 3 Core 와 Enterprise 급의 새로운 버전이 나왔다. 공식 문서가 정말 잘 정리되어 있어 구축시 많은 참고를 할수있었다. 특히 InfluxDB 2 버전부터 Flux 쿼리 문법이 등장했는데 어느정도 방법만 알면 적용할수있을 정도로 설명이 충분하다.
다음으로 InfluxDB의 특화된 장점을 확인해보자. 간단하게 나타내보면 다음과 같다.
- 데이터를 수집하고 쓰기
- 데이터를 쿼리해오기
- 데이터를 가공하기
- 데이터를 시각화하기
- 모니터링과 알림 발송
Grafana
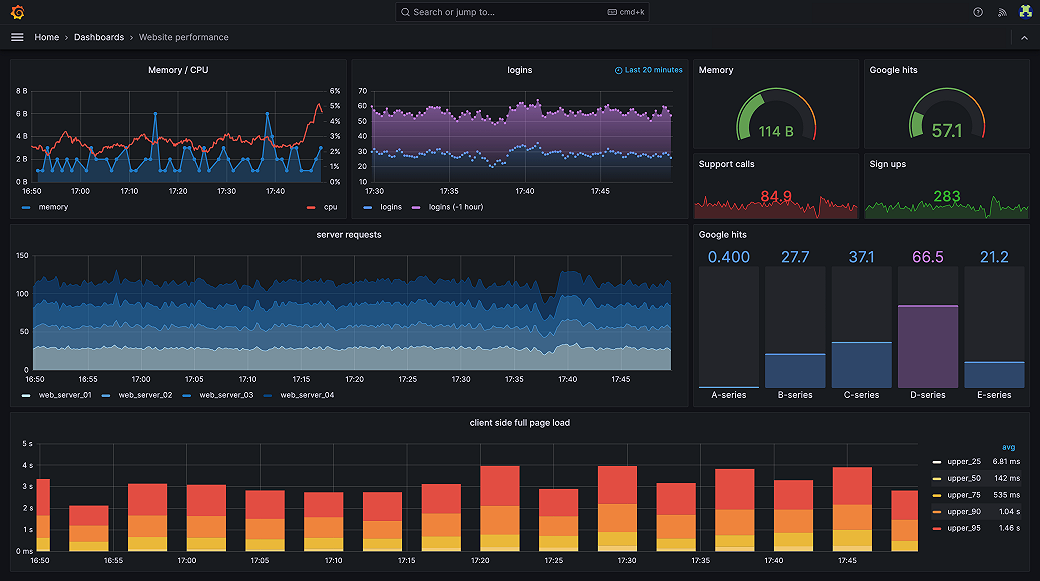
다양한 기능은 공식 문서에 잘 정리되어있다. Grafana 자체 운용부터 Metics, Logs, Trace 까지 다양한 부분에서 지원하고, 현재 기준으로 V12.1이 최신 버전이다.
Stack으로 불리는 이유
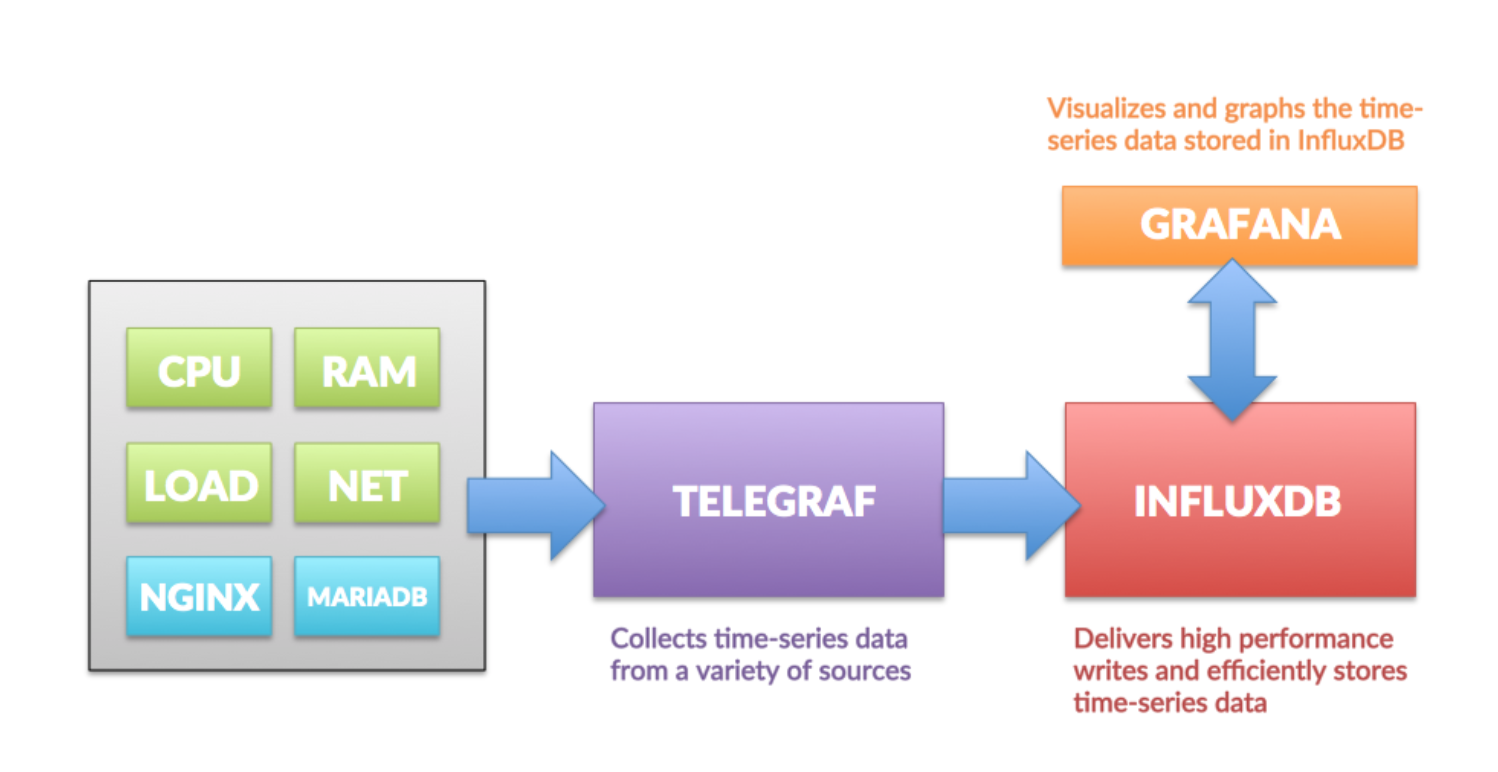
- Telegraf : Metrics와 Events를 수집하고 Reporting 하는 Module
- InfluxDB : Time Series Database
- Grafana : 데이터를 Visualize
또한 Influx Data사에서 자체적으로 제공하는 Tick Stack 조합으로 구성하는 방법도 있어서 간단하게 설명해보면 다음과 같다.
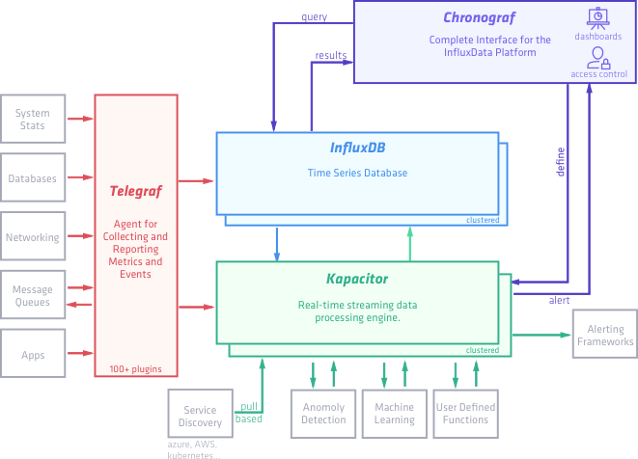
- Telegraf : Metrics와 Events를 수집하고 Reporting 하는 Module
- InfluxDB : Time Series Database
- Chronograf : 시각화 도구
- kapacitor : Real-time 스트리밍 데이터 전송 알람 엔진
이조합으로 사용하는것도 유용하지만 Chronograf를 Grafana로 대체하여 사용하는 조합이 더 많이 사용되는것으로 보인다.
구축과 세팅
서비스 세팅 환경
- InfluxDB Server :
ProxmoxLXC Debian GNU/Linux 10 - Grafana Server :
ProxmoxLXC Debian GNU/Linux 10
사내에서 관리하는 Main Server는 IDC에 Proxmox를 통해 가상환경으로 구성되어, 2개의 서버에 각각 세팅을 진행했다.
InfluxDB 설치
레포지토리 등록
1curl -sL https://repos.influxdata.com/influxdata-archive.key | sudo apt-key add -2source /etc/lsb-release3echo "deb https://repos.influxdata.com/ubuntu $DISTRIB_CODENAME stable" | \4 sudo tee /etc/apt/sources.list.d/influxdb.list설치
1sudo apt-get update && sudo apt-get install influxdb2서비스 시작
1sudo systemctl enable influxdb2sudo systemctl start influxdb위의 단계까지 완료하고 status를 확인해보면 아래 이미지 처럼 active로 동작한다.
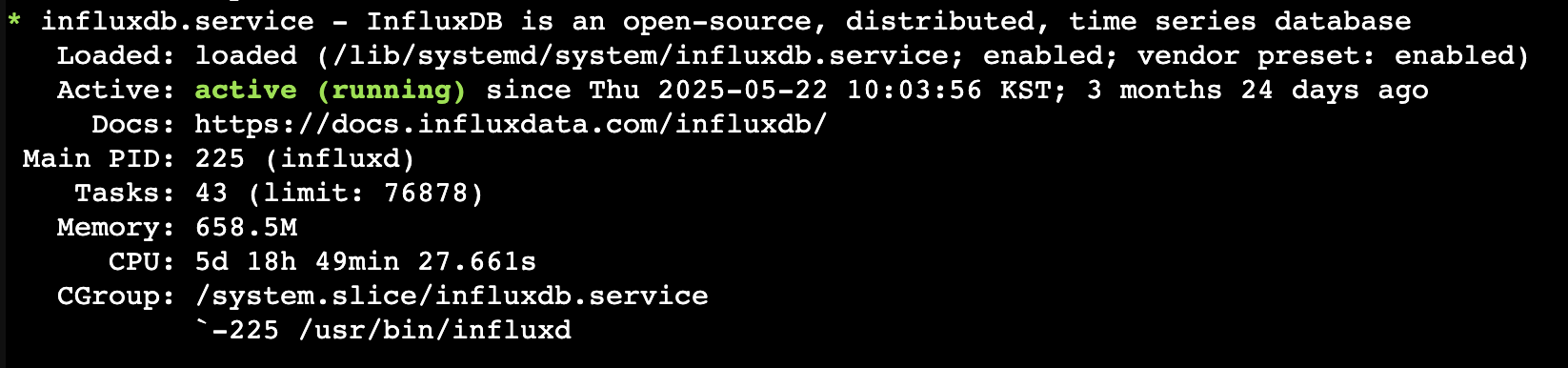
추가설정
1influx setup \2 --username test \3 --password test123 \4 --org test-org \5 --bucket test-bucket \6 --retention 30d \7 --force- --username : 관리자 계정 ID
- --password : 관리자 비밀번호
- --org : 조직 이름
- --bucket : 데이터 저장소 이름
- --retention : 데이터 보관 기간 (예: 30일)
- --force : 이미 세팅된 게 있어도 덮어쓰기
이 방법으로 CLI를 통해 초기 세팅을 진행할수있지만 우리는 GUI로 쉽게 세팅을 진행해보자. InfluxDB의 웹GUI 기본 포트는 8086으로 브라우저를 통해 접속 가능하다.
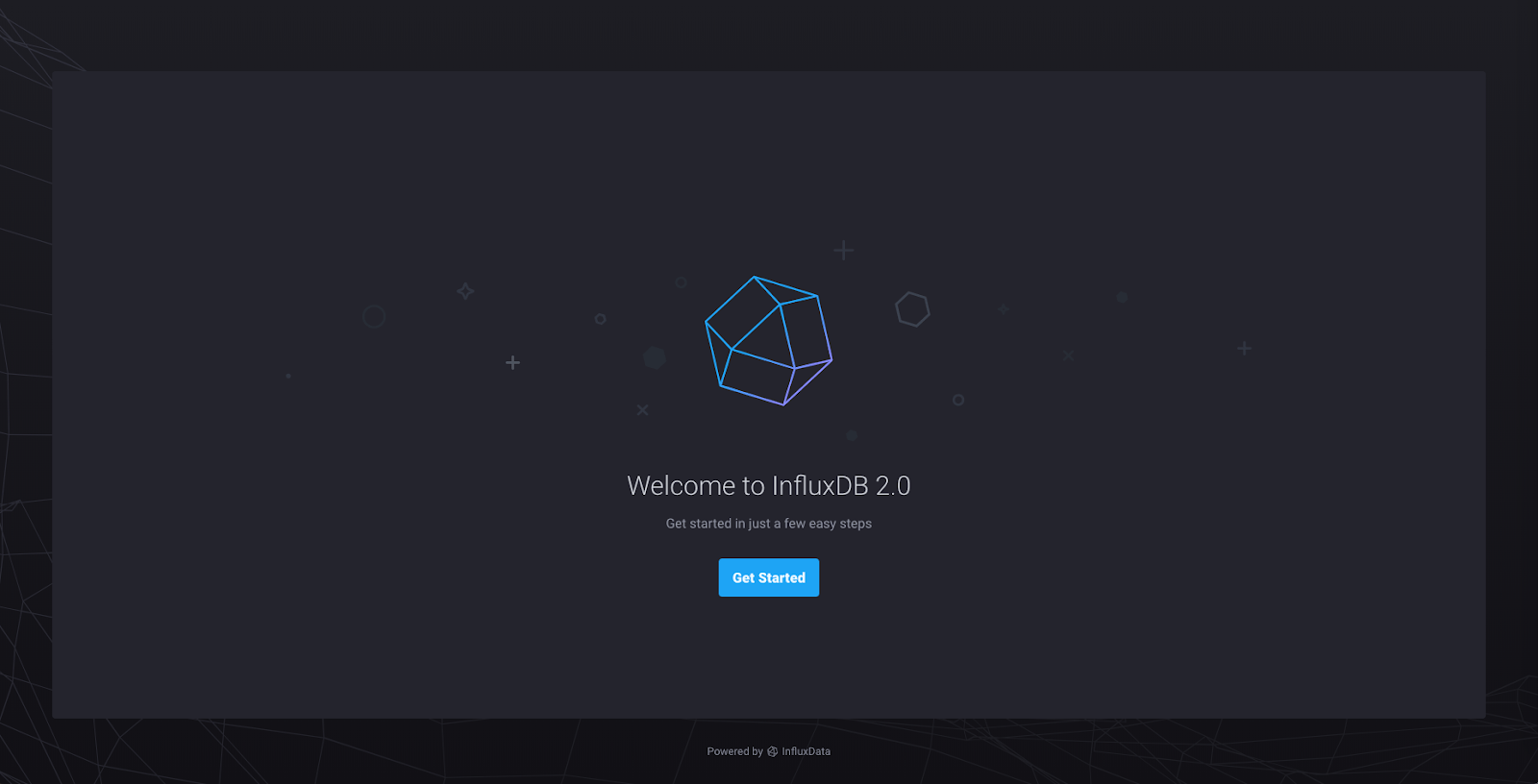
"get Started" 클릭후 이름, 비밀번호, 조직명, 버킷명 등 입력하면 자동로그인 되고 InfluxDB 대시보드 접속이 완료 된다. 자세한 내용은 공식 문서를 참고하면 된다. 좀더 자세히 설명을 해볼까 했지만 문서가 너무 상세히 설명되어있어 링크 첨부로 생략한다.
Grafana 설치
설치
1sudo apt-get install -y apt-transport-https software-properties-common2sudo apt-get install -y adduser libfontconfig13wget https://dl.grafana.com/oss/release/grafana_10.2.3_amd64.deb4sudo dpkg -i grafana_10.2.3_amd64.deb서비스 시작
1sudo systemctl enable grafana-server2sudo systemctl start grafana-servergrafana 대시보드의 기본 포트는 3000번으로 접속이 가능하다. 브라우저를 통해 localhost:3000 으로 접속하면 이미지와 같은 대시보드가 표출된다.
- 기본 계정 : admin / admin
- 처음 로그인 시 새 비밀번호 설정 요구
Telegraf 설치
기본적인 InfluxDB와 Grafana 설치까지 완료 하였으면 다음으로 Telegraf 구축을 진행해보자. Telegraf는 매트릭 수집 에이전트이므로 수집을 원하는 서버에 설치를 진행한다.
레포지토리 동기화
1curl -sL https://repos.influxdata.com/influxdata-archive.key | sudo apt-key add -2source /etc/lsb-release3
4echo "deb https://repos.influxdata.com/ubuntu $DISTRIB_CODENAME stable" | \5 sudo tee /etc/apt/sources.list.d/influxdb.list설치
1sudo apt-get update && sudo apt-get install telegraf서비스 시작
1sudo systemctl enable telegraf2sudo systemctl start telegraf설치가 완료 되었으면 기본설정을 진행하면 된다. /etc/telegraf/telegraf.conf 를 편집해서 InfluxDB와 연결하는 작업을 진행하자.
1# 글로벌 에이전트 설정2[agent]3 interval = "10s" # 수집 주기4 round_interval = true5 metric_batch_size = 10006 metric_buffer_limit = 100007
8# Input plugins (수집할 메트릭 정의)9[[inputs.cpu]]10 percpu = true11 totalcpu = true12
13[[inputs.mem]]14[[inputs.disk]]15[[inputs.net]]16
17# Output plugins (수집한 데이터 저장할 곳)18[[outputs.influxdb_v2]]19 urls = ["http://localhost:8086"]20 token = "여기에_InfluxDB_Token"21 organization = "test-org"22 bucket = "test-bucket"수집 및 저장할 데이터는 플러그인 방식으로 동작하는데 Github에서 플러그인을 확인할수있다. 예시에 작성한 cpu, mem, net 이외에도 많은 종류의 데이터를 지원하므로 필요한 리소스 플러그인을 확인후에 config에 추가하여 수집 하도록 하자.
완료 후 정상적으로 연동 되었는지 확인을 진행해보자. 하단의 명령어를 실행하면 CPU, Memory 등의 메트릭이 터미널에 표출된다. 이데이터는 그대로 Grafana에서 시각화 가능하다.
1telegraf --config /etc/telegraf/telegraf.conf --testGrafana 와 InfluxDB 연동
InfluxDB 자체에서도 대시보드 기능이 있지만 사용자가 원하는 만큼의 시각화를 제공하지는 않는다. 그래서 우리는 이제 부터 Grafana 대시보드에서 InfluxDB와 연동을 통해 InfluxDB에 저장된 데이터를 Grafana에서 표출한다.
순서는 아래의 이미지를 통해 하나씩 따라가면서 진행하면 된다. 먼저 Grafana 대시보드에 접속한다. 그리고 왼쪽의 메뉴에서 Connections > Data Source > Add data source 를 선택한다.
그러면 위 처럼 다양한 데이터 소스가 보인다. 우리는 InfluxDB에 연결할 것이므로, InfluxDB를 선택 하면 된다.
Add new datasource를 클릭하면 상세한 연결 속성을 입력할수있다.
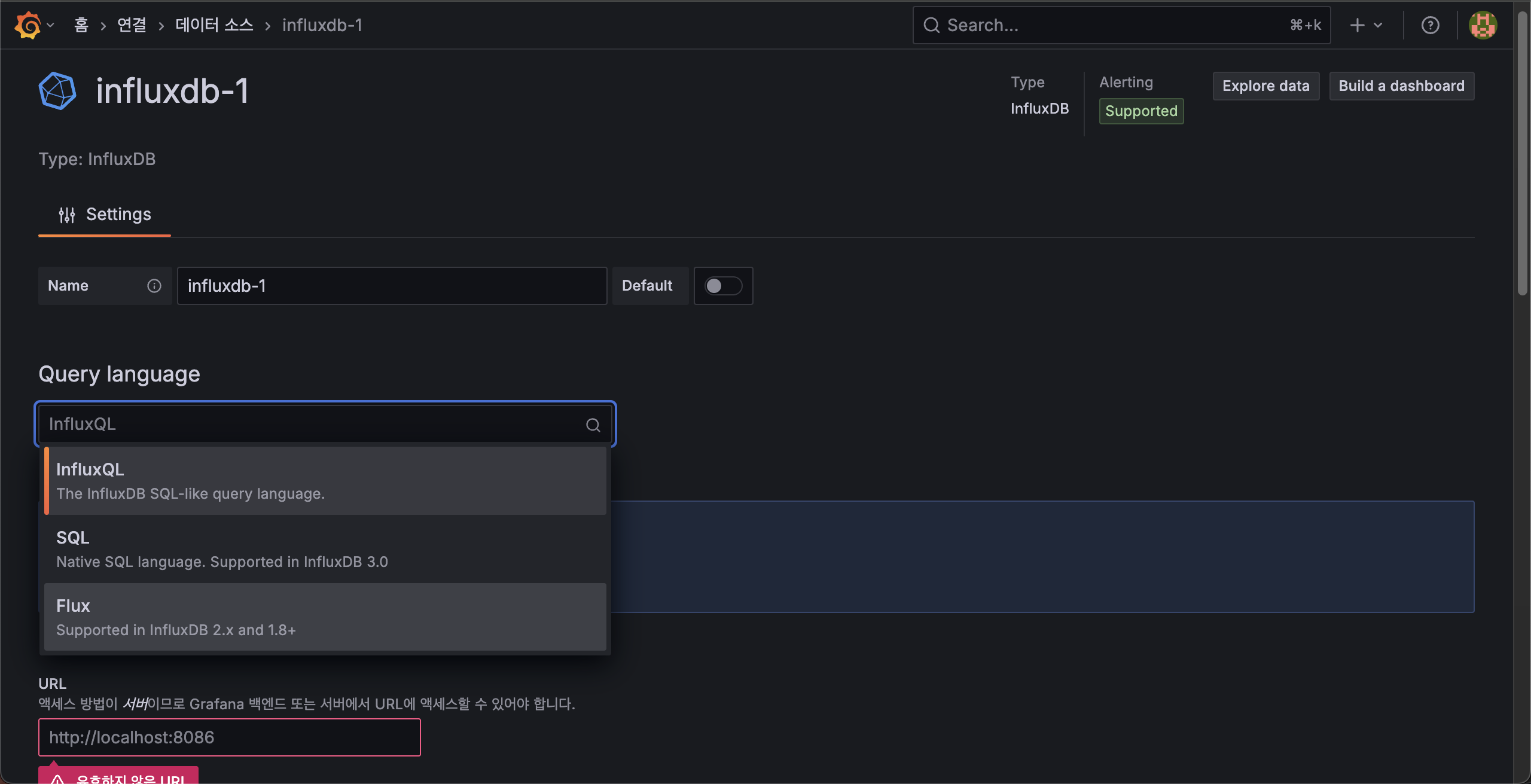
기본적으로 입력해야하는 설정은 다음과 같다.
- Query language : Flux (InfluxDB 2.0 이상)
- URL : InfluxDB 주소
- Organazation : test-org(연결할 ORG)
- Token : InfluxDB에서 발급받은 인증 토큰
- Default Bucket : test-bucket(연결한 Bucket)
이후 Save & Test 버튼을 클릭하고 연결 성공 메세지를 확인하면 된다.
대시보드 생성
DB와 연결이 완료되었으면, 이제부터 Flux 쿼리를 통해 데이터를 시각화할수있다. Dashboards > new Dashboard > Add visualization 메뉴에서 InfluxDB 데이터 소스를 선택하고 쿼리를 작성한뒤, 그래프 / 게이지 / 테이블 등 원하는 시각화를 선택 후 저장한다.
1from(bucket: "test-bucket")2 |> range(start: -1h)3 |> filter(fn: (r) => r["_measurement"] == "sensor_data")4 |> mean()결론
모니터링 시스템에 대해 찾아보고 하나씩 구축해가면서 다양한 경험을 얻을 수있었다. 각 사용자 마다 요구하는 리소스가 달라 블로그 본문은 전체적인 구축 방법에 대해 설명했지만 우리회사에서 필요로 하던 내용을 모니터링 할수있게 구축하면서 큰 보람을 느꼈다. 지금은 개발팀 한쪽에 모니터링 시스템을 구축해 인프라 팀에서 해당 내용을 바탕으로 작업을 진행하는 방향으로 발전했다.